
Web scrapping w PHP
Ciąg dalszy serii artykułów związanych z Lotto. Tym razem pobierzemy najnowsze wyniki z serwisu lotto.pl, pobierając i parsując (analizując) zawartość strony. Nie mam jednak wpływu na to jak pobierana strona wygląda, więc napisany kod działa w dniu pisania artykułu. Jeżeli totalizator zmieni jej strukturę znacząco (mało prawdopodobne) to oczywiście będzie trzeba przeprowadzić analizę od nowa.

Kolejny raz powtórzę, że loterie są przeznaczone dla osób pełnoletnich, a poniższa treść jest jedynie w celach edukacyjnych / rozrywkowych. Zastrzegam również, że nie można przewidzieć wyników losowania.
Ponadto sam proces web scrappingu może być niezgodny z regulaminem strony, a zbyt duża ilość pobrań skutkować problemami po stronie firmy / osoby od której pobieramy w ten sposób dane – np. zawiesić stronę z powodu zbyt dużego obciążenia (może być uznane za atak DDOS) lub przekroczenia limitów hostingodawcy. W skrajnych przypadkach zostaniemy zablokowani lub oskarżeni o działanie na szkodę firmy / spowodowanie strat itd. Należy więc takie operacje robić z głową i na własną odpowiedzialność.
Co trzeba znać przed rozpoczęciem artykułu?
Absoulutne podstawy HTML:

- struktura strony
- tagi (
div, p) - klasy
Podstawy PHP:
- zmienne
- tablice
- klasy
- pętle (
for,while,foreach).
Czego się nauczysz?
- Analizowania struktury strony z wykorzystaniem przeglądarki
- Pobierania zawartości strony z ustawionym nagłówkiem
- Przekształcania strony HTML na obiekt
- Przeszukiwania obiektu po tagach
Przegląd strony
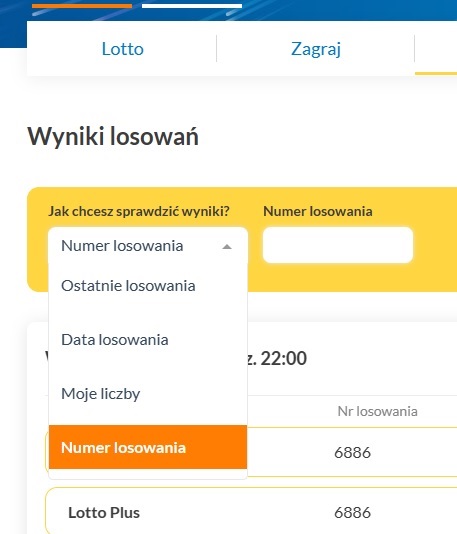
W pierwszej kolejności musimy odszukać stronę na której znajdują się wyniki losowań Lotto. Interesuje nas pole „Jak sprawdzić wynik”. Widzimy, że można to zrobić po:
- numerze losowania
- dacie losowania
lub wyświetlić po prostu ostatnie losowania.
Wystarczy zaznaczyć sposób filtrowania i po prawej wpisać numer losowania. Zanim to zrobimy, sprawdźmy najpierw jaki jest ostatni numer losowania, bo od niego zaczniemy.
Po wpisaniu numeru pojawi się tabela z wylosowanymi w danym losowaniu liczbami oraz datą losowania (na górze).

Po wyświetleniu wyników zostaliśmy przekierowani na stronę:
https://www.lotto.pl/lotto/wyniki-i-wygrane/number,1Jak widzimy adres składa się z pola number po którym (po przecinku) znajduje się numer losowania. Po zmianie numeru w adresie wyświetla się strona z właściwym numerem. To znacznie ułatwia nam zadanie, gdyż wystarczy tylko odpowiednio spreparować adres url.
Dla przykładu, wpisując w pasek przeglądarki
https://www.lotto.pl/lotto/wyniki-i-wygrane/number,6886wyświetlimy losowanie z numerem 6886. Wpisując wyższe numery niż jeden widać, że wyświetla się 10 ostatnich losowań. Po naciśnięciu przycisku „pokaż więcej” ładowane są zaś kolejne (starsze) losowania. W tym konkretnym przypadku „pokaż więcej” się nie przyda.
Analiza kodu strony
W przeglądarkach takich jak Chrome, Edge, Firefox itp. wbudowane są całkiem silne narzędzia do analizowania strony. Osobiście od dłuższego czasu korzystam z Edge (takie czasy, że prywatnie większe zaufanie mam do Microsoftu niż Google), więc pokażę tą analizę na przykładzie właśnie tej przeglądarki (choć wszędzie będzie podobnie).
Zastanówmy się najpierw co potrzebujemy pobrać:
- datę losowania
- numer losowania
- liczby
Ponieważ za jednym zamachem otrzymujemy 10 losowań to nie ma sensu z tego nie skorzystać (zamiast 6886 pobrań możemy wykonać „tylko” 688). Zaznaczmy to co nas interesuje i kliknijmy „Wykonaj inspekcję”

Po prawej stronie szukamy miejsc gdzie są zapisane konkretne, interesujące nas dane (czasami trzeba rozwinąć poszczególne, div-y, ale po najechaniu na element podświetla nam się czego dotyczy.
Spróbujmy znaleźć elementy, które jasno opisują to czego szukamy:
- wszystkie wyniki znajdują się w
<div data-v-940a92d6 class="game-results-container"> - każde losowanie jest w
<div data-v-940a92d6 "game-main-box skip-contrast"> - data znajduje się wewnątrz
<div data-v-940a92d6 class="sg__desc-title"> - numer losowania jest wewnątrz
<div data-v-940a92d6 class="result-item__number"> - wylosowane liczby są wewnątrz
<div data-v-940a92d6 class="scoreline-item circle">
data-v-940a92d6 wygląda dziwnie, a ciąg cyferek sugeruje, że może się zmieniać w czasie. Najbezpieczniej będzie się zapewne skupić na samych klasach.
Schemat działania
- Pobieramy co 10-te losowanie poprzez link np.
https://www.lotto.pl/lotto/wyniki-i-wygrane/number,10 - Pobieramy element
divz klasągame-results-container– wewnątrz znajdują się wszystkie wyniki - Pobieramy wszystkie wystąpienia
divz klasągame-main-box skip-contrast– każdy element to osobne losowanie - Pobieramy wszystkie elementy
pidivz klasami:
<p class="sg__desc-title">– w celu wyciągnięcia daty<p class="result-item__number„> – by wyciągnąć numer losowania<div class="scoreline-item circle„> – wylosowana liczba
Pobieranie strony
Do pobrania strony najprościej jest użyć funkcji file_get_contents
Dużo lepiej jest identyfikować się jako dowolna przeglądarka. Aby to zrobić musimy taką informację przekazać w nagłówku prośby o pobraniu strony (tzw. request header). Osobiście (z przyzwyczajenia) najczęściej do tego typu operacji używam curl, ale czasami może być niedostępny. Zróbmy więc to poprzez wspomniane file_get_contents, ale dodatkowo przekażemy nagłówek.
Nagłówek
Nagłówek zawiera informacje dotyczące tego jaką metodą pobieramy dane, jakich danych się spodziewamy i kim jesteśmy. W nagłówku może być wysyłanych ponadto dużo więcej danych. Jeżeli chcesz możesz samodzielnie sprawdzić co takiego wysyła Twoja przeglądarka np. na tej stronie What HTTP Headers is my browser sending?. Danych jest znacznie więcej, nam wystarczą podstawowe:
Accept-Encoding: gzip, deflate, br
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: https://eskim.pl
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50Wbrew pozorom nie ma tam niczego specjalnie skomplikowanego. W bardzo dużym skrócie chodzi o to, że identyfikujemy się jako przeglądarka, obsługujemy kompresowanie i możemy pobrać strony w html, obrazki itd.
Kod
$opts = [
'http'=> [
'method'=>"GET",
'header'=>"Accept-Encoding: gzip, deflate, br\r\n" .
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7\r\n" .
"Referer: https://eskim.pl\r\n" .
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50\r\n"
]
];
$context = stream_context_create ($opts);
$compressed = file_get_contents ($url, false, $context);
$webpage = gzdecode ($compressed);
print_r ($webpage);Strona została pobrana. Niemniej jest skompresowana w formacie gzip (zezwoliliśmy na kodowanie w nagłówku). Aby ją zdekompresować należy użyć funkcji gzdecode. W celu pobrania strony dodajemy parametry z wykorzystaniem funkcji stream_context_create. Funkcja ta służy do ustawienia tzw. kontekstu strumienia (czyli w ogólności – jego konfiguracji). Sam strumień zaś to po prostu jakiś zasób – plik, strona, drukarka itd.
Na czas testowania polecam po pobraniu zapisać zawartość strony z użyciem np. funkcji file_put_contents.
file_put_contents ('lotto.html', $webpage);Później pobierajmy ten plik wpisując po prostu:
file_get_contents ('lotto.html');Parsowanie strony
Wszystkie dokumenty HTML mają pewną strukturę – nagłówek, treść, różne wewnętrzne elementy, stopka itd. Ta struktura opisana jest w formie drzewa tzw. DOM (Document Object Model). Skorzystam z wbudowanych funkcji w PHP, choć prywatnie korzystałem do tej pory głównie z zewnętrznych bibliotek.
Wróćmy do naszego planu:
- wszystkie wyniki znajdują się w
<div data-v-940a92d6 class="game-results-container">
$website = new DOMDocument();
$website->loadHTML ($page); // zamień stronę na obiekt DOM
$divs = $website->getElementsByTagName('div'); // pobierz wszystkie tagi div
foreach ($divs as $div) {
if ($div->hasAttribute('class') && $div->getAttribute('class') == 'game-results-container') {
$element = $website->saveHTML($div); // zapisz diva w formacie html do zmiennej $element
$result = new DOMDocument(); // utwórz nowy obiekt DOM
$result->loadHTML ($element); // zamień diva na obiekt DOM
break; // przerwij pętlę jak znaleziono i zapisano
}
}
$website = null; // usuń z pamięci cały dokumentW powyższym przykładzie tworzymy nową klasę DOMDocument, która pozwoli na łatwiejszą manipulację obiektami na stronie. Następnie tworzymy obiekt DOM z pobranej strony za pomocą metody loadHTML. Później wyszukujemy wszystkie obiekty div przy użyciu metody getElementsByTagName i sprawdzamy czy zawierają klasę (hasAttribute). Jeżeli tak to sprawdzamy czy nazywa się game-results-container (getAttribute). Jeżeli tak to pobieramy cały div i tworzymy nowy obiekt DOMDocument. Wewnątrz są wszystkie potrzebne dane i bezpieczniej będzie pracować tylko na tym obiekcie.
- Pobieramy wszystkie wystąpienia
divz klasągame-main-box skip-contrast– każdy element to osobne losowanie
$divs = $result->getElementsByTagName('div'); // pobierz wszystkie tagi div
$drawns = [];
foreach ($divs as $div) {
if ($div->hasAttribute('class') && $div->getAttribute('class') == 'game-main-box skip-contrast') {
$element = $result->saveHTML($div); // zapisz diva w formacie html do zmiennej $element
$drawn = new DOMDocument(); // utwórz nowy obiekt DOM
$drawn->loadHTML ($element); // zamień diva na obiekt DOM
$drawns[] = $drawn;
}
}Wykonujemy taką samą operację dla losowań i zapisujemy struktury zawierające losowanie do tablicy $drawns. To podejście jest wprawdzie karkołomne i mniej wydajne, ale dużo łatwiej będzie się poruszać po kodzie. Zamiast tworzyć kilka pętli i kilka razy sprawdzać to samo, mogliśmy oczywiście zrobić wszystko za jednym odczytem. Zwróćmy uwagę jeszcze na klasę game-main-box skip-contrast. Są to tak naprawdę dwie klasy, ale metoda getAttribute pobiera cały ciąg i nie możemy sprawdzać w ten sposób wystąpienia tylko jednej klasy – sprawdzamy cały ciąg.
Mając pojedyncze losowania w tablicy można dużo prościej wyłuskać dane dotyczące konkretnego losowania.
$drawns_result = [];
foreach ($drawns as $drawn) {
$numbers = [];
$data = '';
$nr = '';
$ps = $drawn->getElementsByTagName('p');
foreach ($ps as $p) {
if ($p->hasAttribute('class') && $p->getAttribute('class') == 'sg__desc-title') {
$data = trim($p->nodeValue);
}
if ($p->hasAttribute('class') && $p->getAttribute('class') == 'result-item__number') {
$nr = trim($p->nodeValue);
break;
}
}
$divs = $drawn->getElementsByTagName('div');
foreach ($divs as $div) {
if ($div->hasAttribute('class')) {
$attr = $div->getAttribute('class');
if (strpos($attr, 'scoreline-item') !== false) {
$numbers[] = (int)trim($div->nodeValue);
}
}
}
$drawns_result[(int)$nr] = [
'date' => $data,
'nr' => (int)$nr,
'numbers' => $numbers
];
}Sprawdzamy wszystkie elementy p i div. Dla div-a dodatkowo weryfikujemy czy w atrybucie class znajduje się klasa scoreline-item, bo serwis dodaje czasami inne klasy do tego pola. Korzystamy przy tym z funkcji strpos, która wyszukuje fragmentu w tekście i zwraca numer wystąpienia lub false, jeżeli nie znajdzie tekstu. Jeżeli tekst byłby na początku to funkcja zwróciłaby 0, co jest jednoznaczne z false przy porównaniu != – dlatego korzystamy z operatora !==, Zawartość poszczególnych elementów znajduje się w nodeValue. Dodatkowo usuwamy puste znaki przed i po wartości za pomocą metody trim oraz rzutujemy liczby na typ int (bez tego będą to łańcuchy znaków).
Poniżej wycinek wywołania skryptu:
[8] => Array
(
[date] => Niedziela, 03.02.1957
[nr] => 2
[numbers] => Array
(
[0] => 5
[1] => 10
[2] => 11
[3] => 22
[4] => 25
[5] => 27
)
)
[9] => Array
(
[date] => Niedziela, 27.01.1957
[nr] => 1
[numbers] => Array
(
[0] => 8
[1] => 12
[2] => 31
[3] => 39
[4] => 43
[5] => 45
)
)
Kod na GitHub: lotto-pl-parser
Podsumowanie
- Do analizy strony możemy użyć przeglądarki i wbudowanych w nią narzędzi.
- Stronę możemy pobrać przy użyciu
file_get_contents, a zapisać na dysku przezfile_put_contents. - Aby zdefiniować własny nagłówek dla
file_get_contentsużywamystream_context_createi przekazujemy go do funkcji. - Jeżeli strona jest skompresowana, możemy użyć funkcji
gzdecode. - Do wykonywania operacji na obiektach xml służy klasa
DOMDocument. - Ładowanie strony do obiektu realizujemy za pomocą metody
loadHTML. - Pobranie elementów po tagu wykonujemy metodą
getElementsByTagName. - Sprawdzenie czy istnieje atrybut wykonamy z użyciem
hasAttribute, a pobierzemy jego zawartość za pomocągetAttribute. - W atrybucie
classmoże być wiele klas oddzielonych spacją, dlatego korzystamy z funkcjistrposdo wyszukiwania czy w tagu wystąpiła zadana klasa. - Wartość przeszukiwanego taga znajduje się we właściwości
nodeValue.






Przy okazji pobierania wszystkich wyników Dużego Lotka wyszło, że wyszukiwanie po numerze losowania działa nieco inaczej, niż można zakładać. Dane są pobierane tak naprawdę po dacie losowania. W zamierzchłych czasach zdarzały się dwa losowania w ciągu dnia i próba zwrócenia np. losowania numer 830 powoduje, że w odpowiedzi otrzymujemy losowania od numeru 822-831. Należy wziąć na to poprawkę.
— edit —
Od losowania numer 5214 doszło dodatkowo Lotto Plus. Parser w tej sytuacji zwraca nie 6, a 12 liczb.
Od losowania numer 5797 doszła jeszcze Super Szansa (której już nie ma), ale nie wpływa to na szczęście na skrypt.
— edit —
Zmodyfikowałem kod, który sprawdza czy występuje klasa scoreline-item, bo pojawiły się problemy z Multi Lotkiem Plus. Super Szansa może tym razem spowodować problemy (dodatkowe liczby).